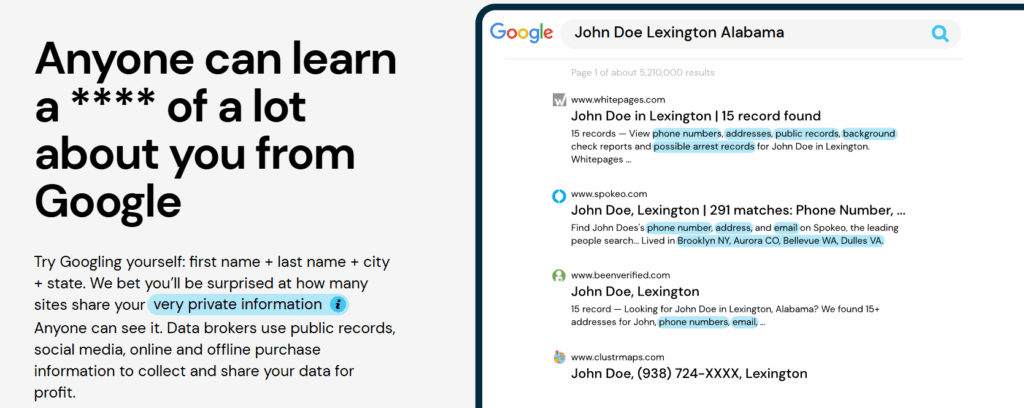
In today’s digital world, personal data exposure is not an exception it’s the norm. Names, phone numbers, home addresses, email IDs, family details, and even past locations are widely available across people-search websites, data broker platforms, and public databases.
In most cases, this information isn’t leaked or hacked. It’s collected, aggregated, and published legally through everyday activities like signing up for services, filling online forms, registering property, or appearing in public records.

This is where many people misunderstand privacy risk. They assume data exposure happens only after a breach, or that removal is a simple one-click action. In reality, personal data removal is a structured, multi-stage process that requires precision, follow-ups, and long-term oversight.
Removing personal information from the internet doesn’t happen instantly and it doesn’t end after one successful opt-out.
Behind the scenes, effective removal follows a continuous cycle: detection → verification → removal → monitoring. Each stage matters, and skipping any part leads to incomplete or temporary results.
This article breaks down how the personal data removal process actually works in practice step by step so you can understand what’s happening behind the scenes, why removals fail, and why ongoing monitoring is essential for maintaining digital privacy over time 🔁🛡️.
📌 What Counts as Personal Data in Online Databases 🧩🔍
To understand how removal works, you first need clarity on what “personal data” actually means in the context of online databases and data brokers. Many people assume it’s limited to obvious details like a name or phone number. In reality, the scope is much broader and more risky.
1. Core Identifiers 🪪
These are the most common and easily searchable data points:
- Full name (including middle names and initials)
- Phone numbers (current and past)
- Email addresses
- Current home address
These identifiers are often enough to locate a person online within seconds.

2. Extended Identifiers 🧠
Data brokers rarely stop at basics. Profiles are often enriched with:
- Names of relatives and household members
- Approximate age or birth year
- Previous home addresses
- Employment or job history
- Education or professional affiliations
Individually, these details may seem harmless. Combined, they create a highly specific personal profile.
3. Why Partial Data Is Still Dangerous ⚠️
A common myth is that “partial information doesn’t matter.” In practice:
- A phone number + city can identify a person
- A name + relative can confirm identity
- An old address can be linked to new records
Data brokers cross-reference fragments across multiple sources, allowing them to reconstruct full identities even when listings look incomplete.
4. How Data Brokers Build Personal Profiles 🧱
Profiles are not copied from one place they are assembled over time:
- Data is collected from public and commercial sources
- Records are matched probabilistically, not perfectly
- Profiles are continuously updated and re-enriched
This is why people often find multiple listings, outdated details, or incorrect associations and why accurate detection and verification are critical before removal begins.
Understanding what qualifies as personal data sets the foundation for the entire removal process. The broader the data footprint, the more structured and persistent the removal effort must be 🔐📊.
📌 Where Personal Data Is Collected From – Overview Table 📊🔍
| Data Source Category | Examples | How Data Gets Exposed | Why It Becomes Publicly Visible |
|---|---|---|---|
| Public Records 🏛️ | Property records, voter registration, court filings, licenses | Collected from government and legal databases | Public transparency laws allow access and resale |
| Utility & Service Signups 🔌 | Internet, phone, electricity, insurance services | Shared with partners or resold via commercial agreements | Terms allow data sharing for business purposes |
| Online Forms & Purchases 🛒 | E-commerce checkouts, warranty forms, surveys | Stored and reused by vendors and marketers | Data retained for marketing and analytics |
| Social Media Metadata 📱 | Location tags, job history, connections | Generated through activity and third-party integrations | Metadata accessible beyond profile privacy settings |
| Marketing & Lead Databases 📊 | Lead lists, CRM exports, affiliate data | Licensed or sold to multiple buyers | Data monetization ecosystems depend on redistribution |
| Data Broker Aggregation 🧩 | People-search sites, background databases | Combined from multiple upstream sources | Aggregation creates enriched public-facing profiles |
| Historical Records ⏱️ | Old addresses, past phone numbers | Never fully deleted from source systems | Legacy data remains searchable and reusable |
This table shows why personal data exposure is rarely caused by a single action. It is the result of layered collection and long-term aggregation, which makes detection and ongoing monitoring essential parts of the removal process 🔐🔁.
Over time, personal data collected from public records, online forms, service providers, and marketing databases is aggregated into unified profiles. Data brokers legally combine and monetize this information by linking identifiers across multiple sources, which significantly increases long-term exposure risk and explains why personal data continues to resurface even after removal.
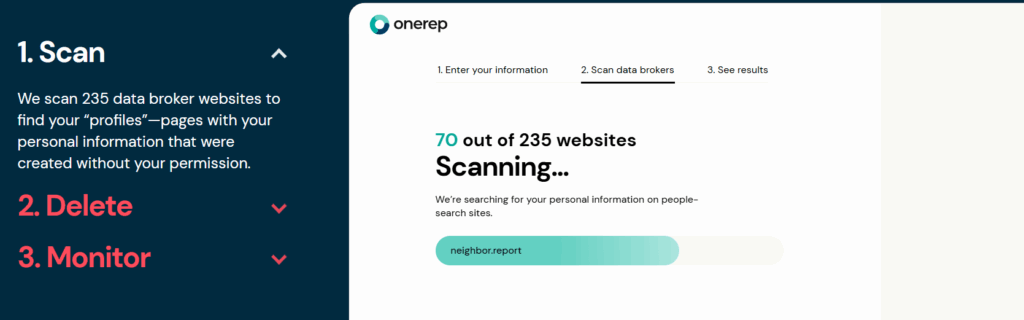
📌 Step 1 — Detection & Internet-Wide Data Scanning 🔎
The first and most critical stage of the removal process is detection. You cannot remove data you don’t know exists.
Most people drastically underestimate how many sites list their information. A quick Google search of your name might reveal a few obvious results, but hundreds of data broker sites don’t appear prominently in search engines. They operate through direct search portals where your data is indexed but not easily discoverable without knowing exactly where to look.
Manual searching is ineffective for several reasons:
- Name variations: Data brokers may list you under different name formats (first + middle, maiden name, nicknames, misspellings).
- Address history: Past addresses from years ago may still generate separate listings, each needing individual removal.
- Duplicate entries: The same site may have multiple profiles for you based on different data sources or time periods.
- Hidden databases: Many sites don’t allow Google indexing, meaning you won’t find them through standard search engines.
Large-scale scanning works by systematically querying hundreds of known data broker sites using all variations of your personal identifiers. This includes:
- Testing name combinations (first, middle, last, maiden)
- Searching all known current and previous addresses
- Checking phone number and email variations
- Cross-referencing age and location combinations
The output is a comprehensive inventory of every discoverable listing across the internet. This baseline is essential it tells you the scope of the problem and establishes what needs to be removed.
Without this detection phase, you’re essentially guessing. You might remove a few visible listings while dozens of others remain active, continuing to expose your information.
📌 Step 2 — Profile Matching & Identity Verification ✅
Once a scan identifies potential matches, the next challenge is verification. Not every result that contains your name actually refers to you.
This is known as the same-name problem. If your name is relatively common, searches may return profiles for other people who share your name, age range, or general location. Attempting to remove these profiles is not only ineffective it can cause rejection of legitimate removal requests because the data broker recognizes a mismatch.
False positives occur when:
- Someone with the same name lives in your city or state
- Historical address overlaps create ambiguous matches
- Name variations (Jr., Sr., II, III) aren’t properly distinguished
- Married names and maiden names create confusion
Accurate matching requires cross-referencing multiple data points:
- Does the age range align?
- Do the listed addresses match your address history?
- Are the associated relatives correct?
- Does the phone number or email correspond to your known contact information?
This verification logic is critical because wrong matches cause removal failures. Data brokers often reject opt-out requests when the information provided doesn’t match their records exactly. Submitting incorrect details can flag your request as fraudulent, making future removals more difficult.
Proper identity verification ensures that removal requests target only your actual profiles, reducing rejection rates and avoiding wasted effort.
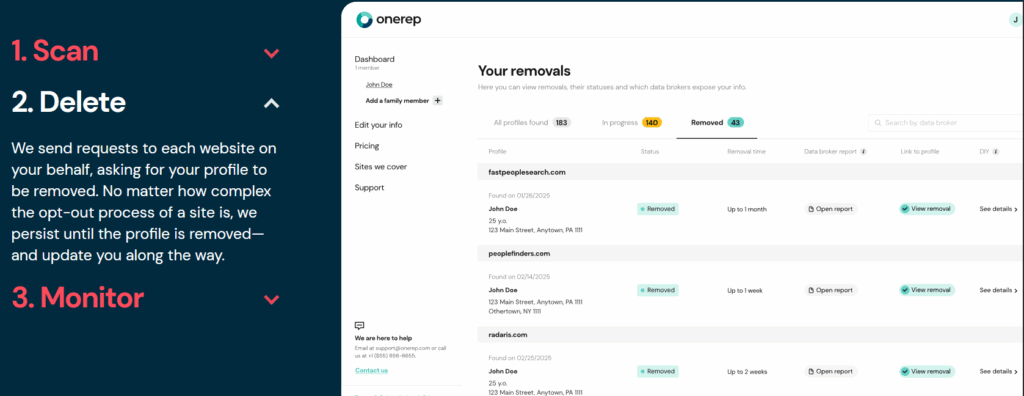
📌 Step 3 — Removal / Opt-Out Request Submission 📤
After detection and verification, the next step is submitting opt-out or removal requests to each site individually.
It’s important to understand what “opt-out” actually means legally. In most cases, data brokers are not required to remove your information unless specific privacy laws apply (such as GDPR in Europe or CCPA in California). However, many sites offer voluntary opt-out processes to comply with consumer expectations or state regulations.
The challenge is that every site has different rules:
1. Form-Based Opt-Outs: Many sites require filling out web forms with exact details (name, address, age, URL of the listing). These forms often have strict formatting requirements and CAPTCHA challenges.
2. Email Requests: Some brokers only accept opt-out requests via email, requiring specific subject lines, proof of identity, or notarized documents.
3. Verification Links: Certain sites send a confirmation email to an address associated with your profile. If that email is outdated or inaccessible, the removal fails.
4. ID Confirmation: Some brokers require uploading a driver’s license, utility bill, or other proof of identity before processing the request. This adds delay and privacy concerns you’re sharing even more personal data to remove existing data.
Manual submission is repetitive and fragile. Each site has unique requirements, processing times, and confirmation methods. A single mistake such as using a slightly different address format or missing a required field can result in silent rejection, where the site simply ignores the request without notification.
For comprehensive removal across 100+ sites, this stage can require dozens of hours and extreme attention to detail. Even then, there’s no guarantee of success on the first attempt.
📌 Step 4 — Follow-Ups, Delays & Confirmation Tracking ⏳
Submitting a removal request is only the beginning. The next phase involves tracking confirmations, handling delays, and following up on unprocessed requests.
Removals are not instant. Processing times vary widely:
- Some sites confirm removal within 24-48 hours
- Others take 7-10 business days
- A few may take 30+ days or never respond
Common delays and silent rejections include:
- Email confirmations that never arrive
- Verification links that expire before you can act
- Sites that claim to process requests but don’t actually remove the listing
- Requests rejected due to minor data mismatches
This is why follow-up is critical. Without re-checking, you won’t know if:
- The removal was actually completed
- The listing has been replaced with updated information
- The site ignored your request entirely
What “successful removal” actually means:
- The specific profile URL now returns a “not found” or “removed” message
- Searches on the site no longer return your information
- The listing doesn’t reappear within a reasonable timeframe
Confirmation tracking involves re-scanning the same sites 1-2 weeks after submission to verify the data is gone. If the listing persists, resubmission or escalation may be required. This iterative process continues until verified removal is achieved.
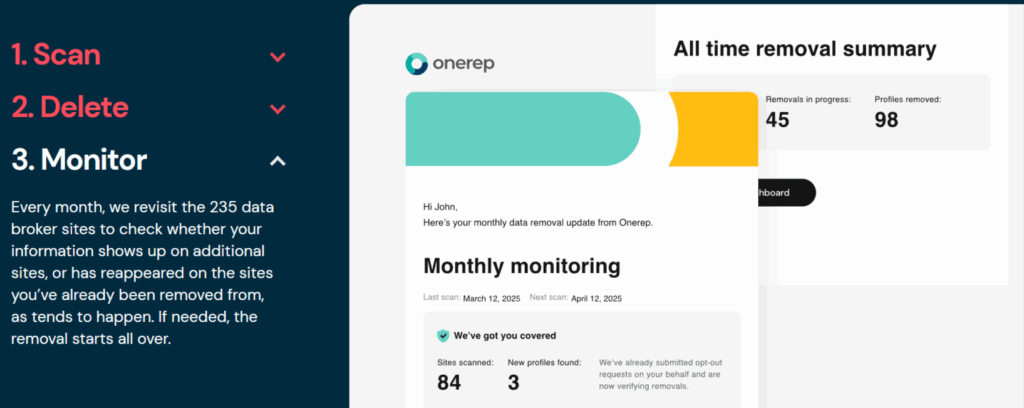
📌 Step 5 — Ongoing Monitoring & Re-Appearance Handling 🔁
Even after successful removal, data comes back. This is one of the most misunderstood aspects of the removal process.
🔹 Why data reappears:
1️⃣ Re-scraping cycles: Data brokers continuously pull information from public records and third-party sources. If a new dataset contains your information, it may be added back to a site you already removed yourself from.
2️⃣ New data sources: Brokers constantly acquire fresh data from new partners, government updates, or purchased marketing lists. These sources may include updated addresses, phone numbers, or other details.
3️⃣ Site updates and mergers: When data broker companies merge, rebrand, or launch new platforms, they often repopulate databases from archived sources, reintroducing previously removed profiles.
4️⃣ Changed information: Moving to a new address, changing phone numbers, or updating voter registration can trigger new listings based on the fresh data.
This is why one-time cleanup fails. You might spend weeks removing your information from 150 sites, only to find 50 new listings appearing within three months.
5️⃣ Ongoing monitoring closes the loop by:
- Regularly re-scanning known data broker sites
- Detecting newly appeared listings as soon as they’re indexed
- Automatically resubmitting removal requests for reappeared data
- Tracking new sites and emerging data brokers
Without continuous monitoring, the removal process resets to zero. Your data gradually repopulates across the internet, and you’re back where you started.
Personal data exposure doesn’t only impact individuals; weak data governance can also contribute to supply chain fraud risks.
📌 Why Personal Data Removal Is Never Truly “Finished” 🔁🔐
A common misconception is that once personal data is removed from a few websites, the job is complete. In reality, personal data removal is never a one-and-done event. It is an ongoing process shaped by how data ecosystems actually function.
Everyday life continuously generates new data:
- Moving to a new address
- Opening new accounts or subscriptions
- Changing jobs or roles
- Interacting with online services
Each event creates fresh records that can later be collected and redistributed.
In addition, data brokers operate on refresh cycles. Even if your data is successfully removed today, it may be reintroduced later when databases are updated or new sources are ingested. Removal does not erase data at the source it only suppresses its public display and resale.
This is why privacy should be viewed as maintenance, not a task. The goal isn’t permanent invisibility, but sustained control over exposure. Ongoing monitoring reduces risk over time by identifying reappearances early and triggering repeat removals before data spreads further 🛡️🔄.
📌 Manual vs Automated Removal (Process Perspective Only) ⚙️🧠
From a process standpoint, manual and automated removal follow the same fundamental steps: detection, verification, removal, and monitoring. The difference lies in scale, consistency, and repeatability.
🖐️ Manual Removal
Manual removal can work when:
- Exposure is limited to a small number of sites
- Data is easy to identify and verify
- Time investment is not a concern
However, manual workflows often break down because:
- Each site has different opt-out rules
- Follow-ups are easy to miss
- Reappearances require repeating the entire process
- Tracking confirmations becomes difficult over time
Manual removal is vulnerable to human error and does not scale well as exposure grows.
🤖 Automated or Structured Processes
Automated or system-assisted approaches support:
- Large-scale detection across many databases
- Consistent verification logic
- Repeatable follow-up and confirmation tracking
- Continuous monitoring for reappearance
This isn’t about speed alone it’s about reliability. When data exposure spans dozens or hundreds of sites, structured processes are the only way to maintain long-term control without constant manual effort 🔁📊.
📌 Common Mistakes People Make During Data Removal ⚠️🚫
Even well-intentioned efforts often fail due to avoidable mistakes. The most common include:
A. Removing the Wrong Profile
Same-name matches and inaccurate assumptions lead to:
- Failed requests
- Removal of unrelated individuals
- Continued exposure of the real profile
B. Using a Primary Personal Email Everywhere 📧
Submitting opt-out requests with a main email address:
- Creates new data points
- Increases future exposure risk
- Connects identities across databases
C. Stopping After the First Success ✅
One successful removal does not mean full coverage. Many profiles remain unseen or reappear later.
D. Confusing Search Engine Removal with Data Deletion 🔍
Removing a result from a search engine only hides the link it does not remove the data from the source database.
E. Ignoring Reappearance Risk 🔄
Without monitoring, removed data can quietly return through:
- Database refreshes
- New broker partnerships
- Re-scraped public records
These mistakes don’t just slow progress they often undo it. Understanding and avoiding them is essential for any effective personal data removal strategy 🛡️📌.
“Related Articles”
- How to Remove Personal Data from the Internet Safely
- Preventing Supply Chain Fraud Through Data Protection
📌 Conclusion 🔐🧠
Personal data removal is not a shortcut, a tool, or a one-time action it is a process mindset. In a digital ecosystem built on continuous data collection and redistribution, exposure is dynamic, not static. This is why effective privacy protection depends on understanding how data moves, how profiles are built, and why removals must be maintained over time.
The real-world removal lifecycle follows a clear loop: detection → verification → removal → monitoring. When any part of this loop is skipped, results become temporary or incomplete. Successful privacy management focuses on control, accuracy, and consistency, not the unrealistic promise of total disappearance.
Long-term risk reduction comes from staying proactive limiting new data exposure, monitoring for reappearance, and responding quickly when information resurfaces. Privacy, in practice, is about maintaining visibility over your digital footprint and reducing unnecessary access to your personal information.
By approaching personal data removal as an ongoing process rather than a final destination, individuals and organizations can make informed decisions, avoid common failures, and build a more resilient digital privacy posture over time 🛡️🔁.
Frequently Asked Questions (FAQs) ❓
1. Can personal data be removed permanently?
No. Data can be suppressed, but it may reappear as databases refresh or new sources are added.
2. Why does personal data come back after removal?
Because data brokers regularly re-collect information from public and commercial sources.
3. Is personal data removal legal?
Yes. Opt-out and removal requests are legally supported in many regions.
4. How often should monitoring be done?
Continuously, or at least monthly, to detect and handle re-appearances early.

Hi, I’m Nelson 👋 a content writer and reviewer with 6+ years of experience writing blogs, coupon guides, and detailed website reviews. I have a strong background in continuous learning and research, which helps me analyze platforms, tools, and websites in a structured and practical way 📚.
My content is based on real research, hands-on analysis, and accuracy, with a clear focus on simplicity, transparency, and user-first value. I aim to break down complex information into content that’s easy to understand and genuinely helpful for readers ✅.